--- Summary:
- Sonnet 4.6 has been released barely a few days after Opus 4.6, and it already feels like the better model.
-
Anthropic released Claude Opus 4.6 to a lot of excitement**, a flagship model with a 1M token context window, Agent Teams in Claude Code, and benchmark results that outperformed GPT-5.2.** But Opus pricing has always been costly for anyone using Claude heavily in production or daily workflows.
-
Now Sonnet 4.6 promised to bridge this gap, with faster responses for coding and longer stretches without hitting limits. I tested it right away, and the first impression was good.
- On GDPval-AA — the benchmark that measures real-world office and knowledge work tasks — Sonnet 4.6 scores 1633 Elo while Opus 4.6 scores 1606.
--- Full Article:
Sonnet 4.6 has been released barely a few days after Opus 4.6, and it already feels like the better model.
Anthropic released Claude Opus 4.6 to a lot of excitement****, a flagship model with a 1M token context window, Agent Teams in Claude Code, and benchmark results that outperformed GPT-5.2.
But Opus pricing has always been costly for anyone using Claude heavily in production or daily workflows.
Now Sonnet 4.6 promised to bridge this gap, with faster responses for coding and longer stretches without hitting limits.
I tested it right away, and the first impression was good.
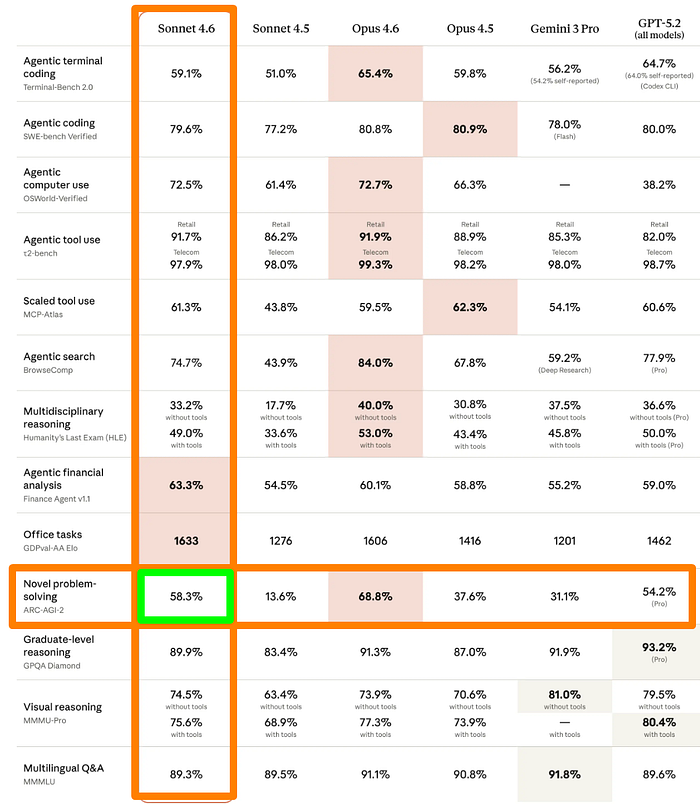
On the benchmarks, it has impressive scores. On GDPval-AA — the benchmark that measures real-world office and knowledge work tasks — Sonnet 4.6 scores 1633 Elo while Opus 4.6 scores 1606.
That one data point reframes the whole conversation around which model you should be using day to day. In my experience, Sonnet models have always been cost-effective.
Sonnet 4.6 also leads on agentic financial analysis, matches Opus 4.6 on computer use, and pulls ahead of Sonnet 4.5 across almost every benchmark category.
In this article, I’ll break down what changed, where Sonnet 4.6 wins, where Opus 4.6 still holds an edge, and what this means for how you use Claude going forward.
Claude Sonnet 4.6

Anthropic describes Sonnet 4.6 as their most intelligent model for everyday use.
This is a step up from Sonnet 4.5 in nearly every category while staying at the same price point.
The improvements cover five core areas:
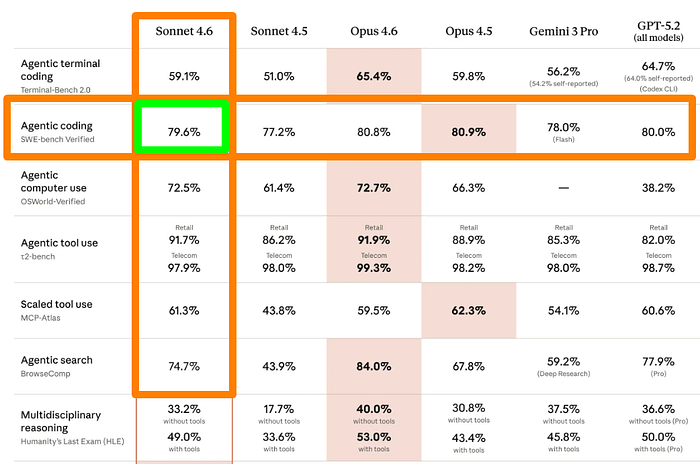
- Agentic computer use — 72.5% on OSWorld-Verified, up from 61.4% on Sonnet 4.5
- Agentic coding — 79.6% on SWE-bench Verified, up from 77.2%
- Office tasks — 1633 Elo on GDPval-AA, beating both Sonnet 4.5 (1276) and Opus 4.6 (1606)
- Agentic financial analysis — 63.3% on Finance Agent v1.1, the highest of any model in the comparison
- Novel problem-solving — 58.3% on ARC-AGI-2, more than four times Sonnet 4.5’s score of 13.6%
Anthropic also highlights improvements to how Sonnet 4.6 handles long-horizon agentic tasks.
Sonnet 4.6 does better in the kind of multi-step, tool-heavy workflows that have currently become the real test for any serious AI model.
The model string for API users is claude-sonnet-4-6. Pricing remains in line with previous Sonnet models.
One thing worth noting: Opus 4.6 still leads on agentic terminal coding****(65.4% vs 59.1%), agentic search (84.0% vs 74.7%), and multidisciplinary reasoning (53.0% vs 49.0% with tools).
If those specific capabilities drive your workflow, Opus 4.6 remains the stronger choice.
But for everything else, especially office work, financial analysis, and computer use, Sonnet 4.6 is the best option.
Claude Sonnet 4.6 Features
Sonnet 4.6 is a improvements touch almost every area of how the model performs, from computer use to coding to long-horizon planning.
Here’s what changed:
1) Computer Use — 72.5% on OSWorld-Verified
Sonnet 4.5 scored 61.4%. Sonnet 4.6 hits 72.5% — an 11-point jump on a benchmark that tests the model’s ability to operate real software interfaces autonomously.
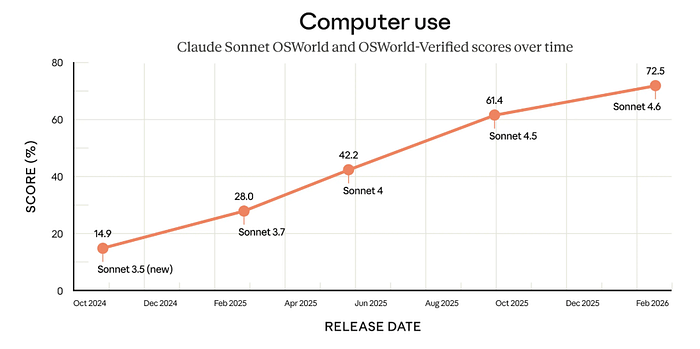
- Sonnet 3.5 (new) scored 14.9% back in October 2024
- Sonnet 4.6 now scores 72.5%.
The trajectory over 16 months is steep, and this release represents the biggest single-version gain in that chart.
For developers building computer-use agents or automation workflows, this is the most reliable model for now.
2) Agentic Coding — 79.6% on SWE-bench Verified
Sonnet 4.6 scores 79.6%, up from 77.2% on Sonnet 4.5. Opus 4.6 scores 80.8%
The gap between Sonnet and Opus on real-world coding tasks is now less than 1.5 percentage points.
On Terminal-Bench 2.0, Sonnet 4.6 scores 59.1% against Opus 4.6’s 65.4% — Opus still leads on agentic terminal work, but Sonnet closes the gap from Sonnet 4.5, which was at 51.0%.
3) Office Tasks — 1633 Elo on GDPval-AA
On this, Sonnet 4.6 is ahead of everyone, including Opus 4.6.
GDPval-AA measures performance on real knowledge work tasks — documents, analysis, structured reasoning across professional domains.
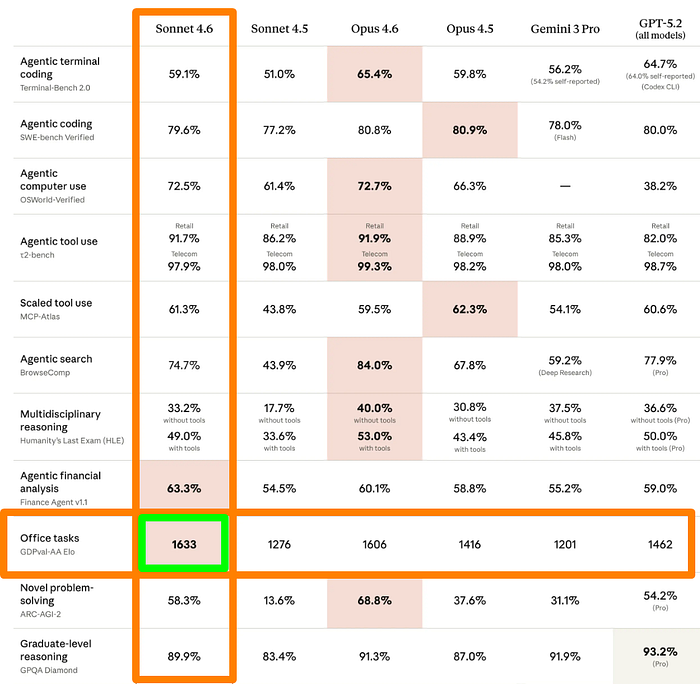
- Sonnet 4.6 scores 1633 Elo
- Opus 4.6 scores 1606
- Sonnet 4.5 was at 1276.
That’s a 357-point jump from Sonnet 4.5 to Sonnet 4.6 on the benchmark.
For business owners, freelancers, and knowledge workers, this is the most relevant number in the comparison table.
4) Agentic Financial Analysis — 63.3% on Finance Agent v1.1
Claude Sonnet 4.6 leads every model on this benchmark:
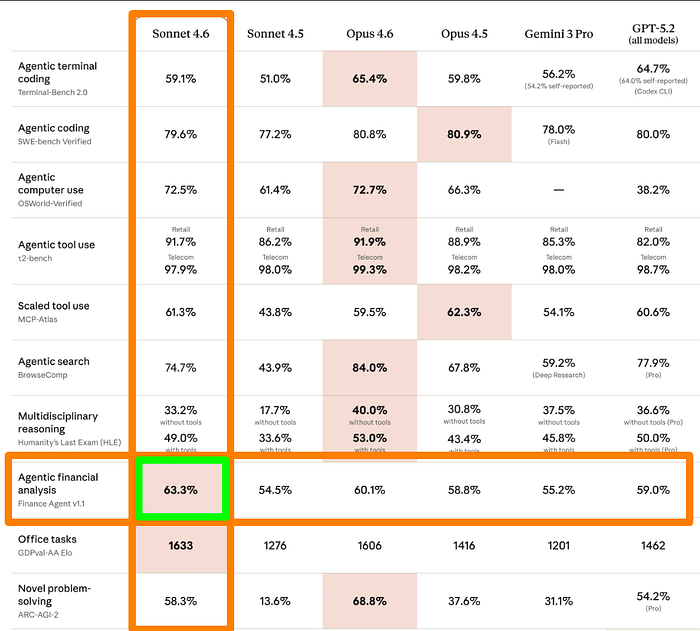
- Opus 4.6 (60.1%), Opus 4.5 (58.8%)
- Gemini 3.0 Pro (55.2%)
- GPT-5.2 (59.0%).
Financial analysis tasks involve multi-step reasoning, data interpretation, and structured decision-making under constraints.
Claude Sonnet 4.6 handles these better than any frontier model tested here, which is a good result for teams using Claude in finance, operations, or data-heavy workflows.
5) Novel Problem-Solving — 58.3% on ARC-AGI-2
Sonnet 4.5 scored 13.6% on this benchmark, while Sonnet 4.6 improves the scope to 58.3%.
ARC-AGI-2 tests the model’s ability to solve genuinely new problems — the kind that can’t be answered by pattern-matching on training data.
A jump of this size in a single version is unusual, and it signals a serious change in how the model approaches problems it hasn’t seen before.
Opus 4.6 still leads at 68.8%, but Sonnet 4.6’s improvement here is the most dramatic in the entire release.
6) Long-Horizon Planning — Vending-Bench Arena
The Vending-Bench simulation runs models through a full year of operating a vending machine business, testing how well they plan, adapt, and manage resources over time.
Claude Sonnet 4.6 ends the simulation with a balance of roughly 2,100.
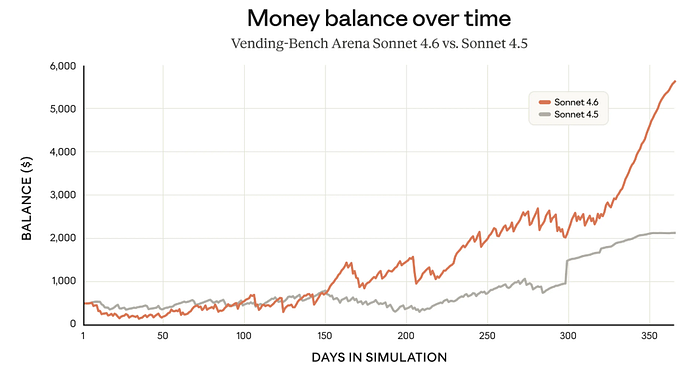
The gap grows steadily from around day 150 onward, with Sonnet 4.6 pulling away sharply in the final quarter of the simulation.
This is a measure of sustained reasoning quality, and the result puts Claude Sonnet 4.6 well ahead of its predecessor.
Claude Sonnet 4.6 vs Opus 4.6
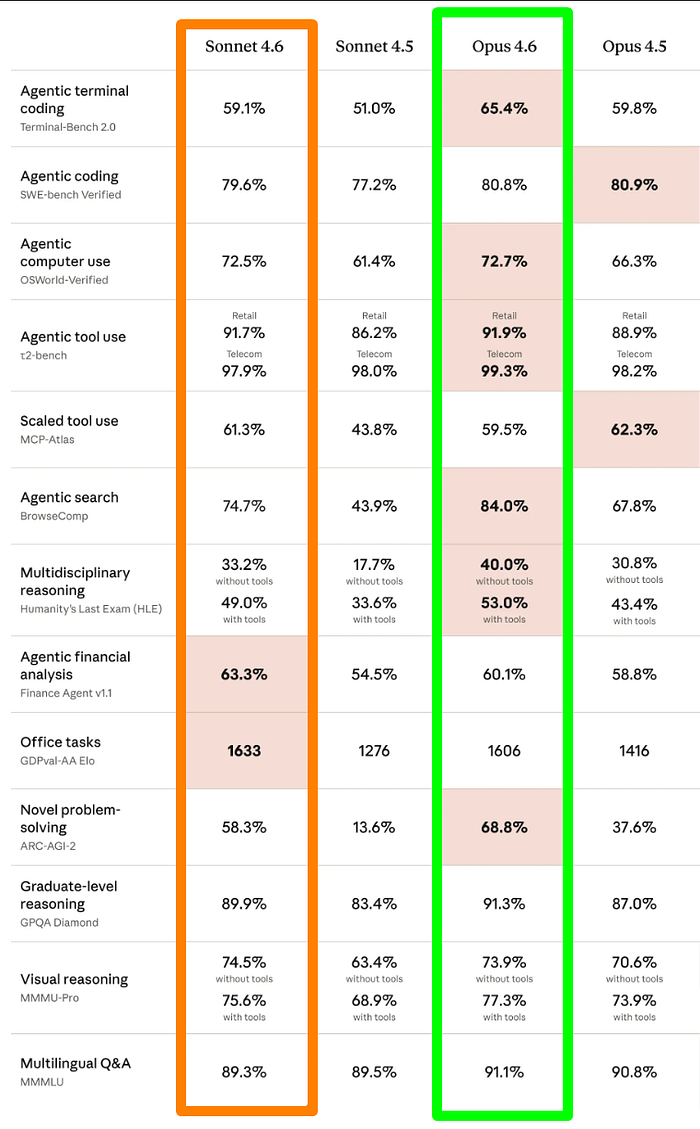
In the scores, Sonnet 4.6 doesn’t sweep Opus 4.6 across the board, but it wins in enough categories that the pricing argument becomes hard to ignore.
Sonnet 4.6 wins:
- Office tasks (GDPval-AA): 1633 vs 1606 Elo
- Agentic financial analysis: 63.3% vs 60.1%
- Agentic computer use: 72.5% vs 72.7% — essentially tied, with Opus holding a 0.2% edge
Opus 4.6 wins:
- Agentic terminal coding (Terminal-Bench 2.0): 65.4% vs 59.1%
- Agentic search (BrowseComp): 84.0% vs 74.7%
- Multidisciplinary reasoning (HLE with tools): 53.0% vs 49.0%
- Novel problem-solving (ARC-AGI-2): 68.8% vs 58.3%
- Agentic coding (SWE-bench Verified): 80.8% vs 79.6%
In summary,
- Opus 4.6 retains its edge in tasks that require deep reasoning, intensive search, and complex terminal-based coding.
- Sonnet 4.6 leads — or matches — on everything closer to professional knowledge work and computer use automation.
For most developers and business users, Sonnet 4.6 wins in the categories they use daily. The Opus 4.6 wins are meaningful but narrower in their practical application.
The 1M token context window remains exclusive to Opus 4.6, which is still the right choice if your work involves massive codebases or extensive document processing.
But if your workflows sit in office tasks, financial analysis, agentic computer use, or general coding, Sonnet 4.6 delivers comparable results at a lower cost.
That’s the key takeaway from this comparison: the performance gap between Sonnet and Opus has narrowed to the point where the choice now depends on your specific use case.
Final Thoughts
Sonnet 4.6 is what people were hoping Opus 4.6 would be: a model that punches at the top tier without the premium cost.
Sonnet 4.6 is the right choice if you:
- Work primarily on office tasks, documents, and knowledge work
- Run financial analysis or data-heavy workflows
- Build or use computer agents
- Want strong agentic coding performance without Opus pricing
- Run Claude heavily in production, where the cost per token adds up
Claude Opus 4.6 is the right choice if you:
- Work with codebases or documents exceeding 200K tokens (1M context window)
- Need the best possible agentic terminal coding performance
- Run deep research or hard search tasks regularly
- Require maximum reasoning depth on complex multidisciplinary problems
For most people reading this, Sonnet 4.6 is the best foe for your daily coding work. If you’re already on a Claude plan, switch to Sonnet 4.6 and test it :
If you are using the API, the model string is claude-sonnet-4-6. I’ll be running a full hands-on coding comparison of Sonnet 4.6 vs Opus 4.6 in my next article.
If you’ve already tested it, share your thoughts in the comments — I’m curious whether the benchmark results hold up on real tasks.
Claude Code Masterclass Course

Every day, I’m working hard to build the ultimate Claude Code course, which demonstrates how to create workflows that coordinate multiple agents for complex development tasks. It’s due for release soon.
It will take what you have learned from this article to the next level of complete automation.
New features are added to Claude Code daily, and keeping up is tough.
The course explores Agents, Hooks, advanced workflows, and productivity techniques that many developers may not be aware of.
Once you join, you’ll receive all the updates as new features are rolled out.
This course will cover:
- Advanced subagent patterns and workflows
- Production-ready hook configurations
- MCP server integrations for external tools
- Team collaboration strategies
- Enterprise deployment patterns
- Real-world case studies from my consulting work
If you’re interested in getting notified when the Claude Code course launches**,****click here to join the early access list →**
(Currently, I have 5000+ already signed-up developers)
I’ll share exclusive previews, early access pricing, and bonus materials with people on the list.
Let’s Connect!
If you are new to my content, my name is Joe Njenga
Join thousands of other software engineers, AI engineers, and solopreneurs who read my content daily on Mediu m and on YouTube where I review the latest AI engineering tools and trends . If you are more curious about my projects and want to receive detailed guides and tutorials , join thousands of other AI enthusiasts in my weekly AI Software engineer newsletter
If you would like to connect directly, you can reach out here:
Follow me onMedium | YouTube Channel| X| LinkedIn