I spent 8 hours understanding Apache Spark’s memory management | by Vu Trinh | Feb, 2026 | Medium
Sign up
Sign up

Member-only story
I spent 8 hours understanding Apache Spark’s memory management
Here’s everything you need to know

Follow
9 min read
·
4 days ago
126
3
Share
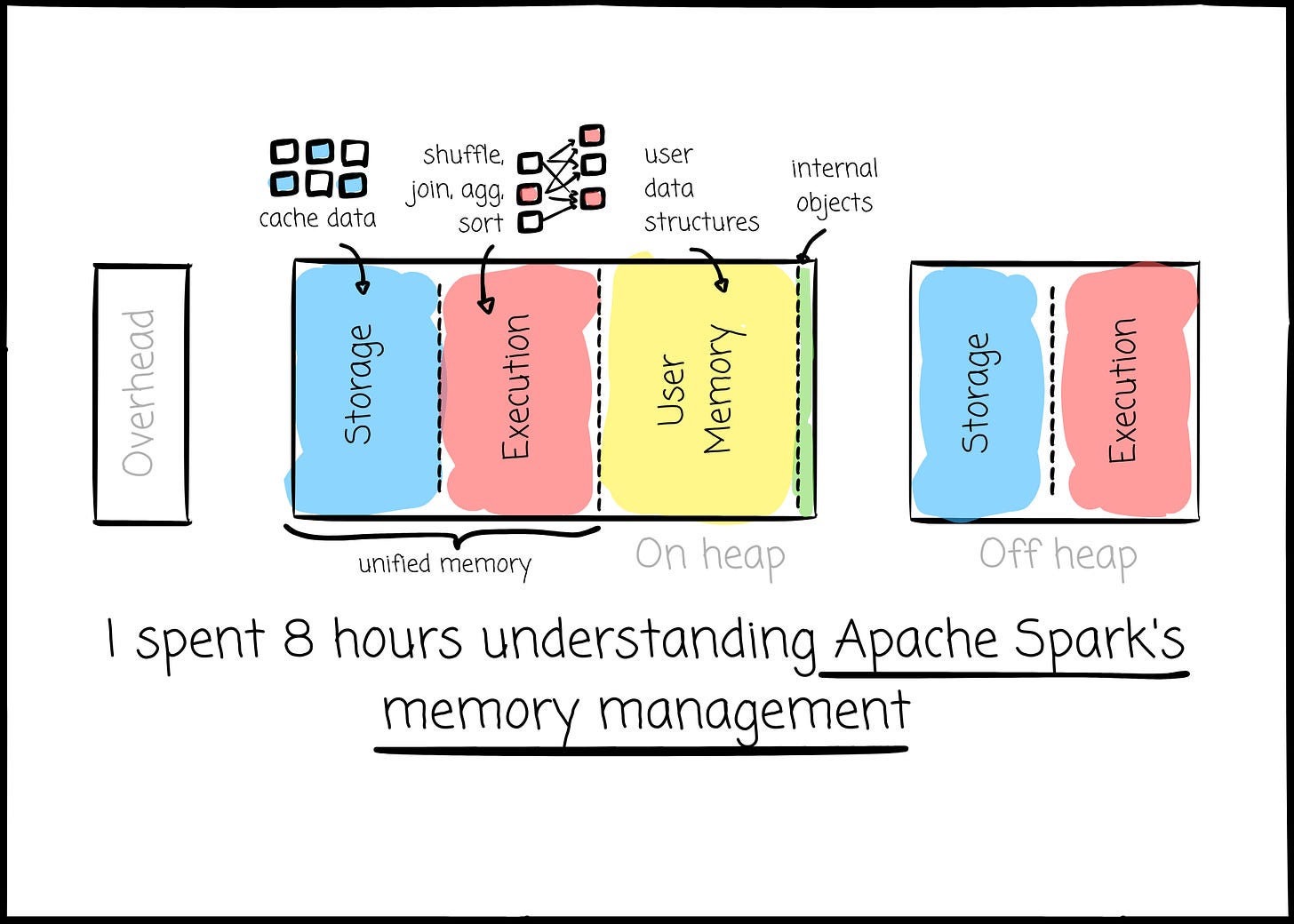
Intro
In 2009, UC Berkeley’s AMPLab developed Spark.
At that time, MapReduce was the go-to choice for processing massive datasets across multiple machines. AMPLab observed that cluster computing had significant potential.
However, MapReduce made building large applications inefficient, especially for machine learning (ML) tasks requiring multiple data passes.
For example, the ML algorithm might need to make many passes over the data. With MapReduce, each pass must be written as a separate job and launched individually on the cluster.
They created Spark. Unlike MapReduce, which writes data to disks after every task, Spark relies on memory processing.
With a more friendly API, supporting wide use cases, and especially efficient in-memory processing, Spark has gained increasing attention and become the dominant solution in data processing.
But, do you know how Spark manages the memory?
This week, I will try to answer this question in the following text. We will revisit some Spark basics before diving into Spark’s memory management.
A Spark Application
Create an account to read the full story.
The author made this story available to Medium members only.
If you’re new to Medium, create a new account to read this story on us.
Or, continue in mobile web
Sign up with email
Already have an account? Sign in
126
126
3


Follow
Written by Vu Trinh -------------------
Follow for practical data engineering articles with self-created illustrations. No AI-writing content
Follow
Responses (3)
Write a response
Cancel
Respond

Well explained
—
Reply

Thanks for saving my 80 hours.
—
Reply

I’m a regular reader of content. Awesome stuff as usual. Which software do you use for creating the images.
—
1 reply
Reply
More from Vu Trinh

In
by
I spent 5 hours learning Unity Catalog. Here’s everything you need to know. --------------------------------------------------------------------------- The famous catalog service from Databricks, and it was open-sourced
Jan 21

In
by
The new observability stack war in 2026 --------------------------------------- For years, SRE/DevOps and infra felt like two separate lanes.
Jan 12
In
by
Top 10 Data Engineering Projects That Actually Get You Hired ------------------------------------------------------------ Most beginners build projects that look great on YouTube thumbnails but are useless on resumes.
Dec 15, 2025
In
by
To start the DE career again, I will keep these 4 things in mind ---------------------------------------------------------------- To break into the field quickly and grow more efficiently.
Jan 8
Recommended from Medium


Databricks Just Dropped 22 Game-Changing Features in January 2026 — Here’s What You’re Missing ---------------------------------------------------------------------------------------------- If you’re still running Databricks like it’s 2025, you’re leaving money, time, and competitive advantage on the table
6d ago

In
by
Data Engineering Design Patterns You Must Learn in 2026 ------------------------------------------------------- These are the 8 data engineering design patterns every modern data stack is built on. Learn them once, and every data engineering tool…
Jan 5

The 5 paid subscriptions I actually use in 2026 as a Staff Software Engineer ---------------------------------------------------------------------------- Tools I use that are (usually) cheaper than Netflix
Jan 19

In
by
As a Neuroscientist, I Quit These 5 Morning Habits That Destroy Your Brain -------------------------------------------------------------------------- Most people do #1 within 10 minutes of waking (and it sabotages your entire day)
Jan 14

In
by
Stop Memorizing Design Patterns: Use This Decision Tree Instead --------------------------------------------------------------- Choose design patterns based on pain points: apply the right pattern with minimal over-engineering in any OO language.
Jan 29


LinkedIn Is Replacing Kafka — Here’s Why the Streaming Giant is Moving On ------------------------------------------------------------------------- Inside LinkedIn’s Bold Move to a New Data Pipeline That Could Change the Future of Real-Time Streaming
Jan 3