--- Summary:
- _**AI didn’t remove the data engineer from the loop.
- It pulled the role closer to decisions with real consequences.
- This article explains what that shift means for your role, not in terms of titles or tools, but in terms of responsibility.**_ _Not a Medium Member?
- Read the complete blog for FREE:_ AI in Data Engineering Every few years, the role of the data engineer is declared obsolete.
--- Full Article:
AI didn’t remove the data engineer from the loop. It pulled the role closer to decisions with real consequences. This article explains what that shift means for your role, not in terms of titles or tools, but in terms of responsibility.
Not a Medium Member? Read the complete blog for FREE: AI in Data Engineering
Every few years, the role of the data engineer is declared obsolete. Managed Hadoop was supposed to remove operational complexity. Cloud data warehouses promised to eliminate infrastructure concerns. ELT tools turned pipelines into a configuration. Now, AI copilots are expected to finish the job and make the role itself unnecessary. The prediction keeps changing, but the work does not.
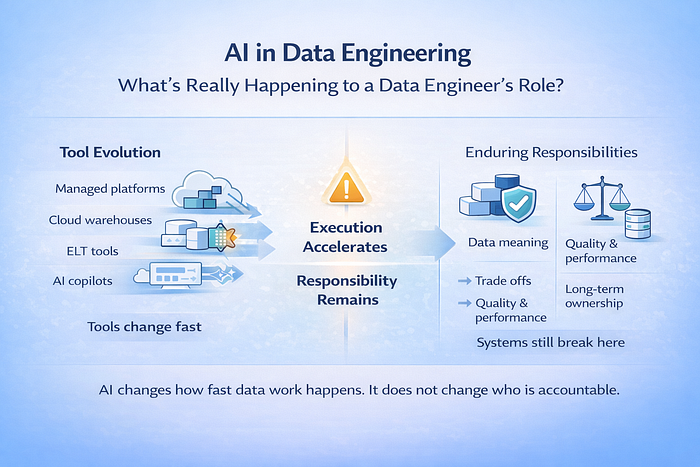
Even as platforms change and vendor names rotate, the underlying constraints of data systems remain stubbornly consistent. Data still needs structure, it still needs validation, it still needs to be queryable at scale, and it still needs to support real decisions made by real businesses. The hype cycles move fast, but the fundamentals move slowly.
AI for Data Engineering excels at producing outputs, but ownership still sits elsewhere. Context does not live in prompts. Trade-offs cannot be inferred from syntax. Long-term responsibility begins where automation stops.
Most data systems do not fail because the code was difficult to write. They fail because decisions were made quickly, without clarity about who would rely on them later. AI shifts this dynamic by compressing time. The same choices are made, only faster, and their impact spreads further.
These failure points are not new. They existed before today’s tools and will persist after them. AI changes the tempo of data work, but it does not change where systems tend to break.
The question facing data engineers is no longer if AI will change the work. It already has. The more useful question is what parts of a data engineer’s role were never about execution in the first place, and why those are now more visible than ever.
The sections that follow examine what is changing, what is not, and how the role of the data engineer is changing as AI becomes embedded in the workflow.
AI is not replacing data engineers. It is exposing which parts of the job were never optional. AI changes the tempo of data work but the boundaries of a data engineer’s responsibility remain exactly where they have always been.
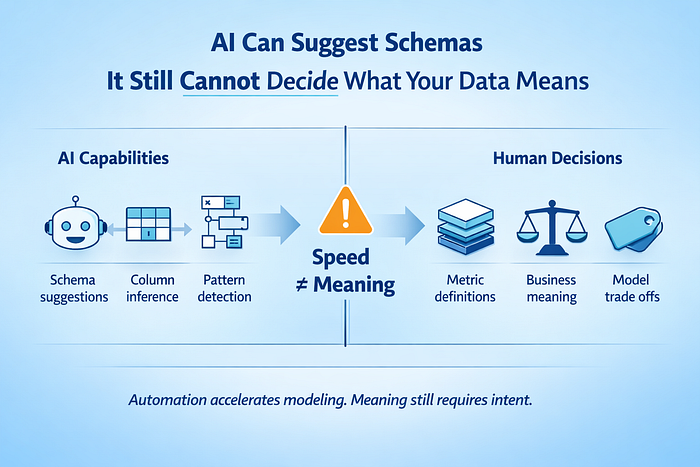
1. AI in Data Engineering Can Suggest Schemas, but It Cannot Decide What Your Data Means
Modern data platforms make schema creation trivial. Tables can be generated instantly. Columns can be inferred. Relationships can be guessed based on observed usage. None of this resolves ambiguity.
Over time, data modeling has shifted away from strict normalization toward pragmatic structures. Snapshot tables replace slowly changing dimensions. Partitioned fact tables and overwrite strategies simplify historical handling. These patterns exist because they reduce operational burden while preserving analytical usefulness.
AI for Data Engineering fits neatly into this trend. Schema recommendations surface quickly. Column groupings are inferred from query patterns. Inconsistencies are flagged before they propagate across downstream models. The acceleration with AI in data engineering is real, but the understanding is not.
Every system that claims intelligence still depends on explicit meaning. A semantic layer has to exist somewhere. Metric definitions require agreement. History needs a declared shape. Decisions around granularity, ownership, and interpretation must be made before automation becomes useful. AI can propose options, but it cannot arbitrate trade-offs.
Correctness versus flexibility. Performance versus generality. Simplicity versus expressiveness. These are decisions shaped by business context, data volume, and how the data will be consumed six months from now. No prompt contains that context by default.
The choice between a star schema and a wide table is secondary to the clarity of purpose behind the model. AI reduces time to output, but context decides if the output remains useful under real production-workloads.
2. The Real Risk in AI for Data Engineering Is Incomplete Data
Modern data ecosystems amplify small mistakes. As organizations ingest more sources, definitions multiply. As data pipelines grow, transformation paths branch. As consumers increase, interpretations drift. Data quality issues rarely arrive as obvious failures. They surface as subtle inconsistencies that compound quietly across systems.
AI for Data Engineering improves detection, anomalies are flagged faster, validation rules can be generated automatically, and distribution shifts are surfaced before dashboards break. Visibility improves, but meaning does not.

Records can be technically correct and still be unusable. A transaction without a timestamp, a customer without a region, a product without classification. Schema checks pass, but null thresholds stay within limits. Decision-making stalls. AI systems trained on incomplete data inherit those gaps without hesitation. Models optimize confidently against partial reality, reinforcing assumptions that were never validated at the point of capture. This is where data engineer’s job role still remains essential.
Quality is not enforced downstream, but it is designed upstream. Field selection, definition alignment, and ownership clarity determine whether data can support future questions. Some attributes cannot be reconstructed later, regardless of how advanced the processing layer becomes.
AI accelerates feedback loops, but it also accelerates the cost of ambiguity. Without intentional capture and validation, uncertainty flows downstream untouched, only now at a higher speed and broader scale.
3. AI Can Write Queries, but it Cannot Keep Dashboards Fast
Dashboards rarely launch slowly, but degradation happens quietly. As usage grows, filters expand, joins accumulate, and access patterns drift. Queries that once returned in seconds stretch into minutes, not because the system failed, but because assumptions expired.
AI for Data Engineering improves query generation. SQL can be written instantly, execution plans can be analyzed automatically, and optimization suggestions can surface faster than before. Speed improves, but stability does not guarantee itself.
Indexes still need to be chosen deliberately. Pre-aggregated tables still matter when query patterns stabilize. Materialized views still exist because workloads repeat in predictable ways. Elastic compute masks inefficiencies temporarily, until cost makes them visible. Performance remains a design problem, not a syntax problem.
Understanding how data is accessed matters more than how quickly queries are produced. As consumption evolves, performance requires intervention. AI accelerates iteration, but it does not prevent performance drift.
4. AI didn’t Kill Batch Processing, but it reinforced it.
Data pipeline counts have exploded. Large organizations routinely operate hundreds or thousands of workflows. Orchestration platforms exist because manual coordination stopped scaling years ago. AI in Data Engineering further reduces friction by generating DAGs, handling retries, and managing dependencies more efficiently. Execution improves, but the underlying model remains.
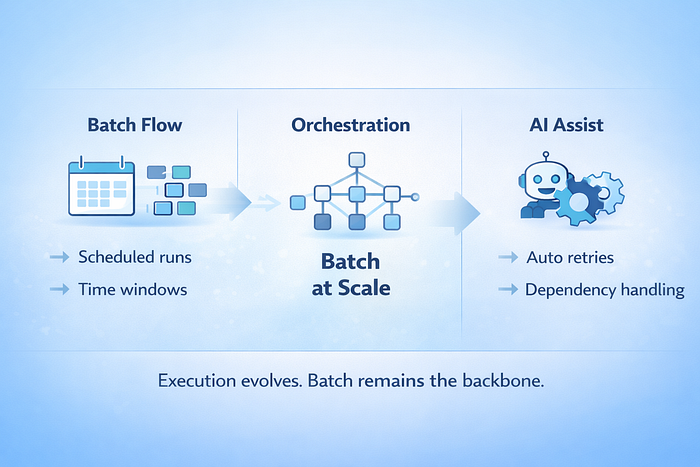
Most analytical data still moves in batches. Scheduled ingestion, windowed transformations, and periodic refreshes into warehouses and lakes. Streaming systems have matured and serve clear operational use cases. Analytics, reporting, and planning continue to align with batch because businesses operate in cycles, not event streams. The scheduling technology has changed, but the execution pattern has not.
AI improves reliability and speed, but it does not eliminate the need for predictable, repeatable data movement.
5. AI in Data Engineering Makes the Wrong Work Faster
Execution has rarely been the limiting factor, but relevance always was and will akways be. AI in Data Engineering reduces the cost of building pipelines, models, and queries. Delivery accelerates across the board, but misalignment accelerates with it.
AI in data engineering makes it easier to build things quickly. It does not make it easier to build the right thing, or to keep it running six months later.
AI may have made a data engineer’s work look deceptively simple. SQL appears instantly, data pipelines are scaffolded from prompts, and schema suggestions arrive before teams have fully agreed on definitions. From the outside, it can feel like the hardest parts of a data engineer’s job have been finally automated.
The reality looks different in production. AI accelerates execution, but acceleration has side effects. Faster iteration reduces friction while quietly increasing the cost of poor decisions. Data systems still require coherence, metrics still need shared meaning, and shortcuts still accumulate interest, only now at a higher speed and wider scale. This is where replacement narratives begin to weaken.
Data systems disconnected from active business priorities decay quickly. Faster pipelines do not compensate for an unclear purpose. Larger models do not create value in isolation.
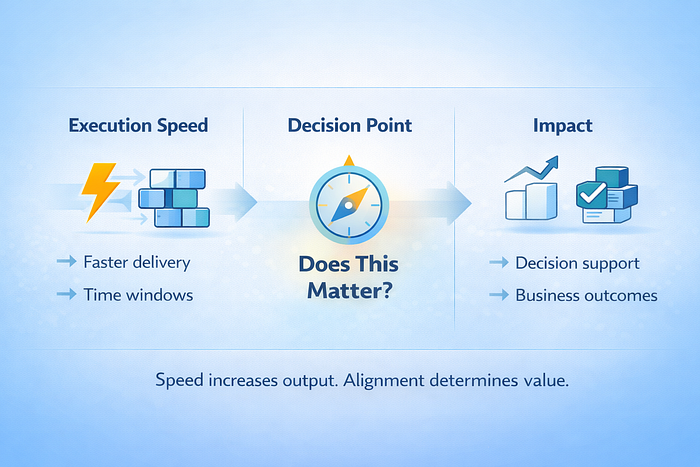
Every organization runs multiple initiatives simultaneously. Data work that supports decision making persists; work that does not quietly loses priority, regardless of technical quality. AI amplifies productivity, but it does not create alignment. Successful data teams translate business questions into durable systems. Tools change but human judgment remains central.
Will AI Replace Data Engineers?
AI has changed the tempo of data engineering. Execution is faster, iteration is cheaper, and more of the workflow is now automated. AI does not and will not replace data engineers. The parts of data systems that determine success or failure remain unchanged. Meaning still has to be defined. Quality still has to be designed in. Performance still requires intent. Alignment still decides whether the output influences real decisions. AI fr sure compresses time but data engineers are and will remain accountable.
As AI becomes embedded in day-to-day workflows, the role of the data engineer moves closer to these decisions, not further away from them. The work shifts from writing everything by hand to deciding what is worth stabilizing, what deserves trust, and what trade-offs the system can afford.
Staying effective in this environment is less about chasing every new tool and more about building the right mental models. ThisAI Data Engineering Roadmap helps frame that progression, not as a list of technologies to learn, but as a way to understand where AI fits, where it does not, and how your responsibilities as a data engineer evolve alongside it. The tools will keep changing, but the role will keep shifting. The data engineers who stay relevant are the ones who understand why.